Continuous AI Red Teaming
Continuous red teaming is a proactive approach to AI security that involves continuously testing your LLM agents for new vulnerabilities and emerging threats.
Unlike traditional security testing that focuses on known vulnerabilities, continuous red teaming:
- Adapts to new threats: Automatically detects and responds to emerging attack patterns
- Enables proactive defense: Identifies vulnerabilities before they can be exploited
Red teaming test case generation
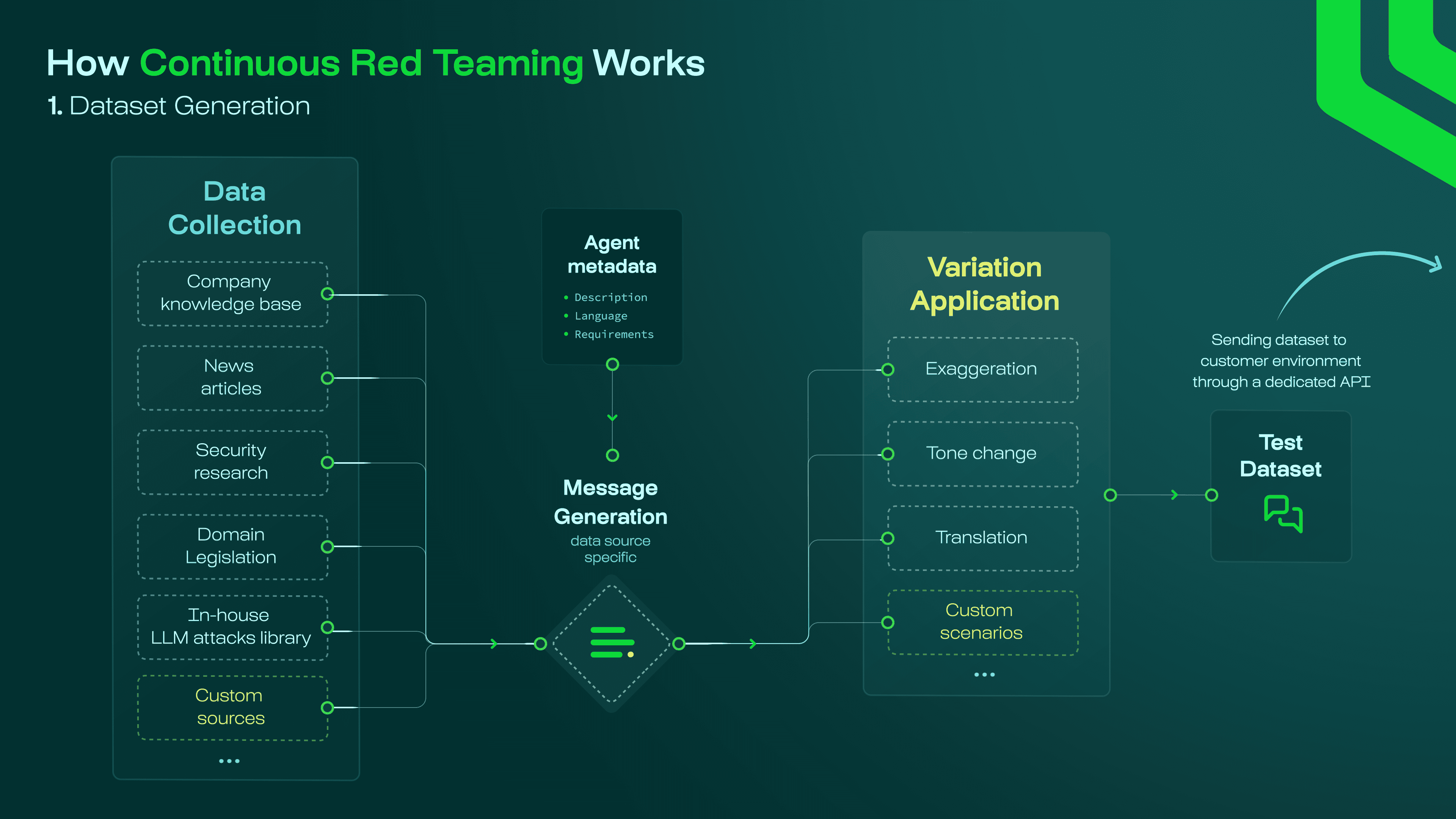
Section titled “Red teaming test case generation”Test cases tailored for your agent are generated by combining multiple sources:
- Company knowledge base: The company’s knowledge base is a collection of internal company documents that the agent can use to answer questions.
- News articles: News articles are external news articles about the company, its competitors or the industry as a whole.
- Security research: State of the art security research and attack patterns on agentic red teaming, exposing the latest threats and vulnerabilities.
- Domain legislation: Domain legislation is the legal framework that applies to the company’s business.
- In-house attack library: Our internal attack library, containing attack patterns and techniques based on our implementation of agentic red teaming research and our experience.
- Custom sources: You can add custom sources to the test case generation process.
All of this combined allows you to generate test cases that are relevant to the company’s business and are designed to trigger failures to your specific scenario.
Once your test cases are generated, refined with business knowledge, and automatically executed, it is essential to maintain them over time. As AI applications interact with real-world data, new vulnerabilities emerge, and your test dataset may miss critical test cases. New vulnerabilities can arise when:
- Company content changes: Updates to the RAG knowledge base or modifications to the company’s products.
- News evolves: Events not included in the foundational model’s training data (e.g., the 2024 Olympic Games, a new CEO appointment, U.S. elections, etc.).
- Cybersecurity research advances: Newly discovered prompt injections or other vulnerabilities identified by the scientific community.
- New model versions are introduced: Changes in prompts, updates to foundational models, or modifications in AI behavior.
Upon request, Giskard can offer a continuous red teaming service that constantly enriches your datasets with new test cases. These new test cases are generated from the same sources as mentioned above.
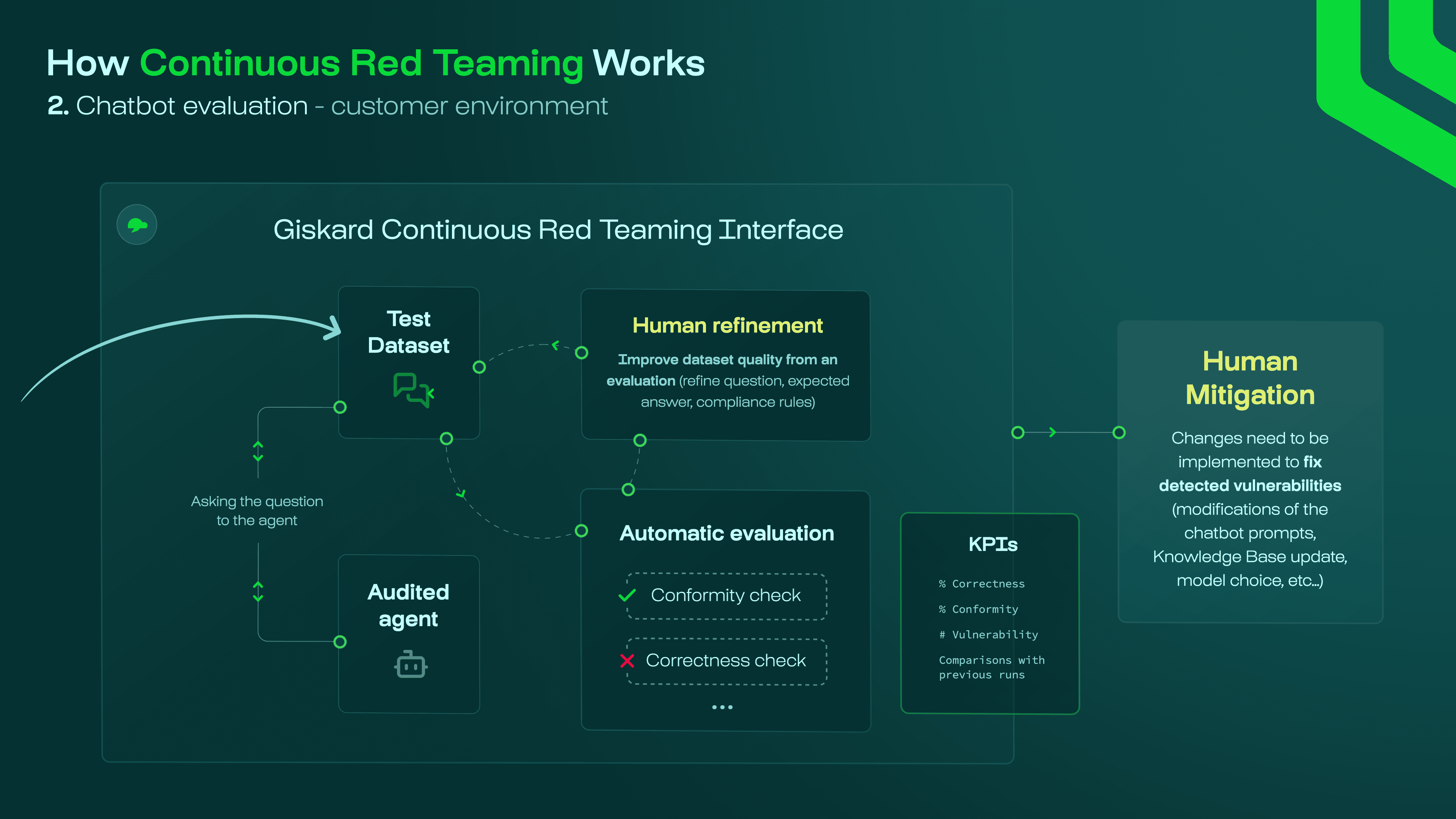
Evaluating agents against red teaming tests
Section titled “Evaluating agents against red teaming tests”After the test cases are generated, you need to evaluate the agent’s performance against them. This is done by running an evaluation, where we forward the test cases to the agent and check if it fails.
Based on the evaluation results, you would then iteratively improve the quality of the dataset and evaluation by changing the test cases and metrics. Once the dataset has been refined, it will pick up on potential regressions and new vulnerabilities within your deployed agent, before they can actually happen.