🔍Giskard Evaluator¶
Leverage the Hugging Face (HF) Space to easily scan and evaluate your Nature Language Processing (NLP) models on HF.
This is a guide to evaluate a model with a dataset on HF with the Giskard Evaluator.
We are currently only supporting Text Classification models. More models are coming…
Obtain Model ID and Dataset ID¶
First, find the model ID of the model you want to evaluate. For instance, locate the model cardiffnlp/twitter-roberta-base-sentiment-latest and click on the “Copy” icon next to the title to copy the model ID:
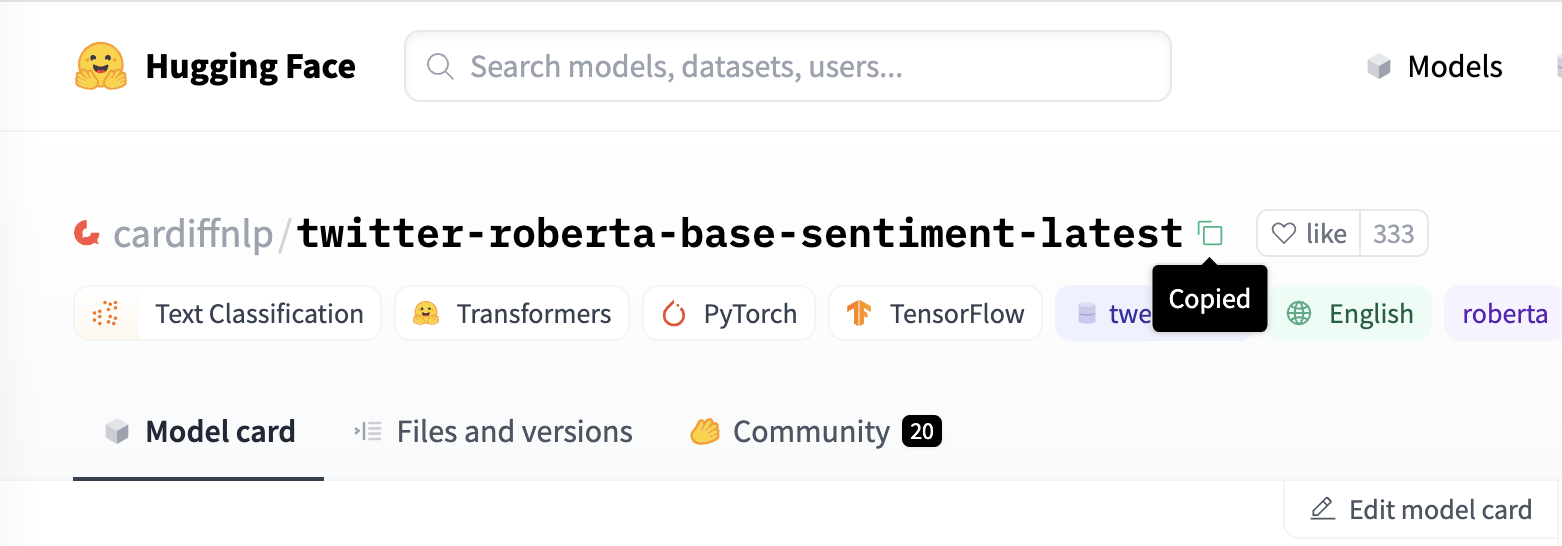
If you want to upload your own model for the evaluation, please check the Hugging Face documentation. A task tag such as text-classification is a must in the metadata for our evaluation. We strongly recommend to add more metadata to your model card.
Next, paste the model ID into the “Hugging Face Model id” space. If the model had already been submitted for a scan before, the related datasets can appear in the suggestion list of “Hugging Face Dataset id”.
You can input any dataset hosted on Hugging Face that matches the model. You can also evaluate with one of your own datasets: check this document to find out how to upload one on Hugging Face.
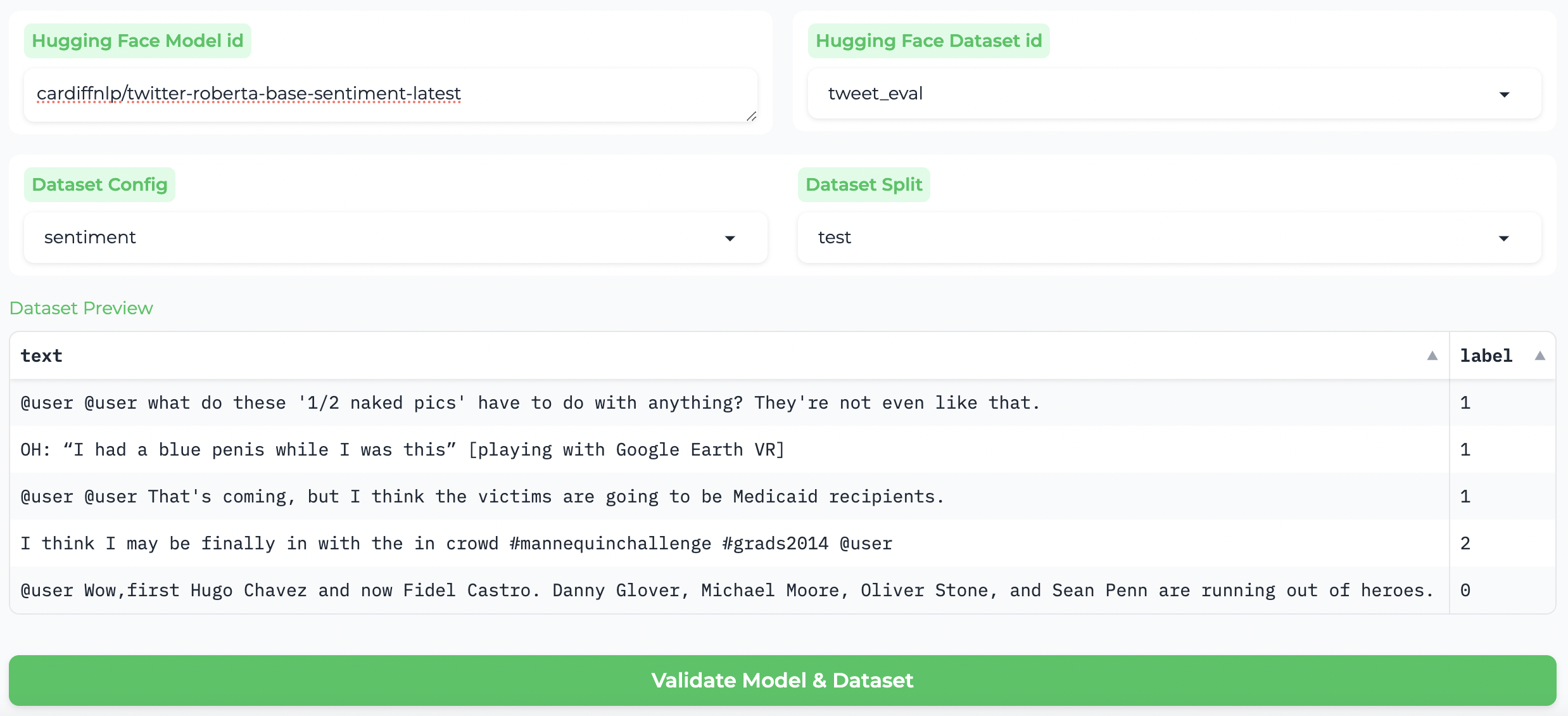
After choosing the model ID and the dataset ID, select the configuration and dataset split – these will get filled in automatically by the first choice, but you might want to evaluate on a specific subset or split.
Please preview the features and double check your choices in the “Dataset Preview” section.
Validate: label and feature matching¶
Once you are done setting up the model and dataset IDs with the configuration and split, you are able to click the validation button below.
We will run a quick prediction with the first row in the dataset to make sure that:
the dataset contains the features needed by the model;
the classification labels of the model can match the labels in the given dataset;
the model and the dataset are compatible with the Giskard open-source library.
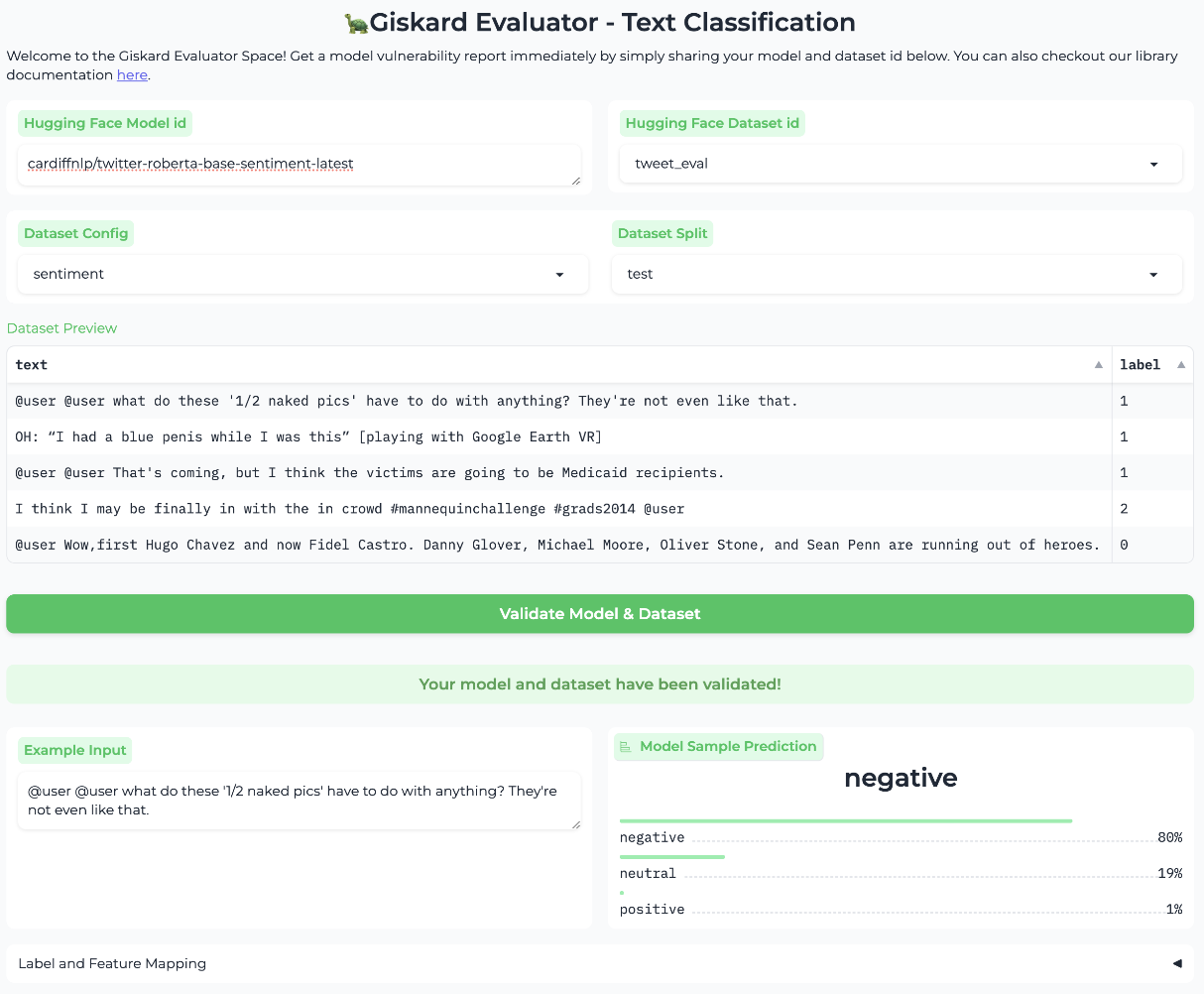
We try our best to match the labels and features in the model and the dataset, however, the dataset might not perfectly match the model and you may have to manually align the features or the labels.
Choose the feature¶
For instance, if your dataset has more than one feature column, you may need to manually guide us to the right one. In the example below, we could map sentence to text instead of idx.
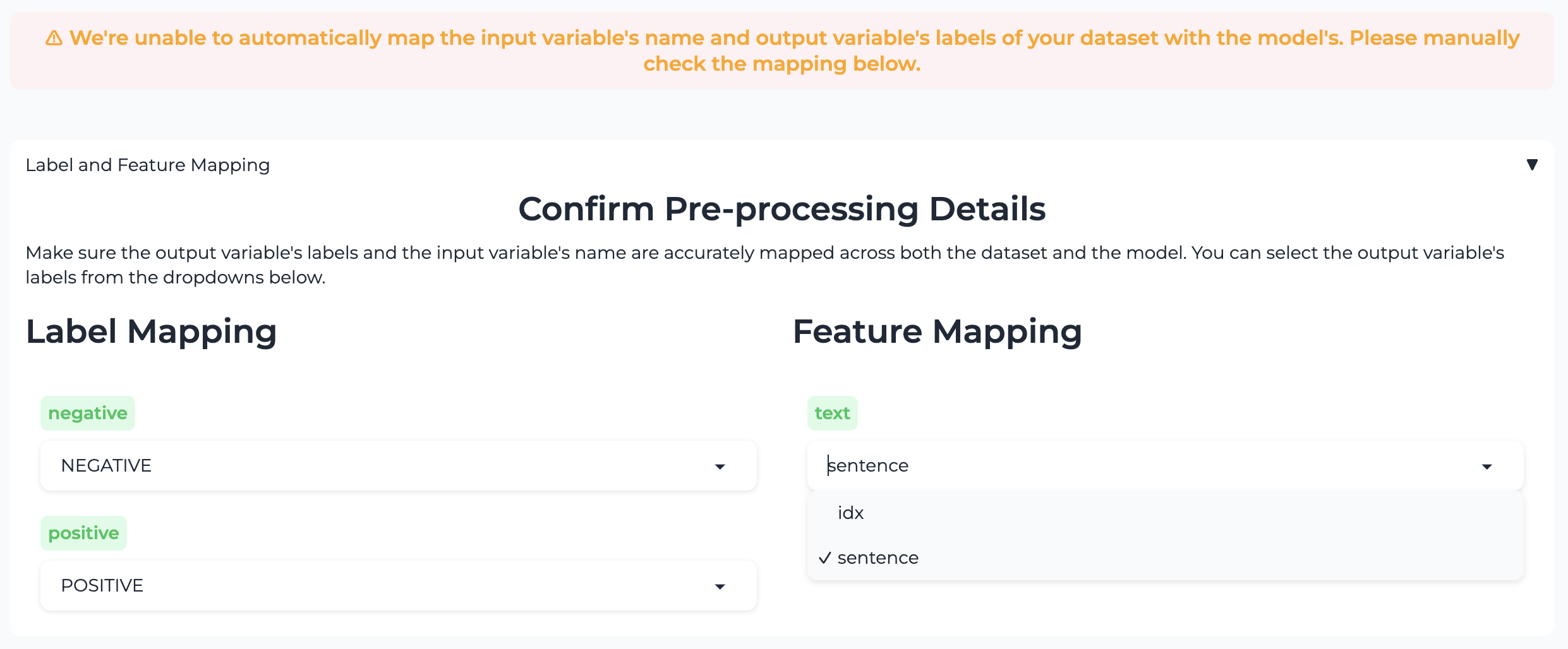
Although this does not stop you from evaluating, it will significantly impact the accuracy of the scan during the evaluation or make the results irrelevant.
Match the labels¶
For instance, if your model is sorting on sentiment data, but the configuration is a set of index for emojis, the labels will not match up.

You need to choose the classification label based on the semantic meanings. After changing to the correct selection in the label mapping, the validation pop-up will turn green!
Use your HF access token for HF inference API¶
The Giskard evaluator leverages the free HF inference API to evaluate the models. To keep the availibility, HF comes up with a rate limit for each user.
You need to fill in your Hugging Face token, to get the best speed by avoiding the rate limits.

The token will only be used in your own evaluation. You can check our code for any concerns.
Finally, click on the “Get Evaluation Result” button to submit your job to the waiting queue and you will obtain the job ID of your evaluation.

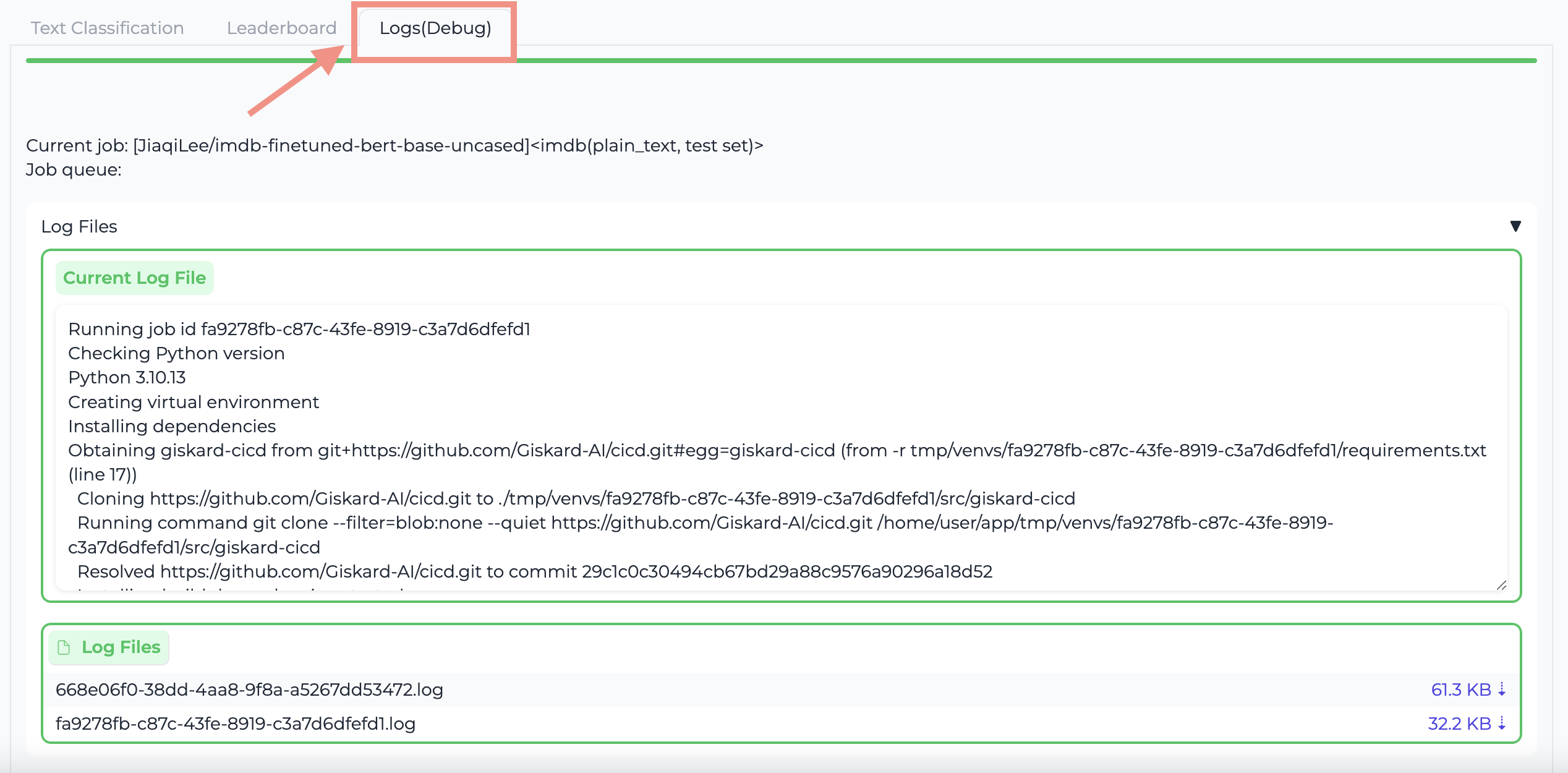
Check evaluation progress¶
You can always come back later to check your job progress in the “Logs” tab.
Once your job has finished, you will be able to find the scan report in the model’s community discussion page.
In case of error, you can download the log file with the job ID from the Giskard Evaluator Space to check the error.
Advanced Configurations (Optional)¶
There are some advanced configurations in the Space:

You can enable the “verbose mode” to check any problems in the scanner during the evaluation of your model. The community tab of this Hugging Face Space is open to your feedbacks.
You can pick the scanners you need for your evaluation. By default, we don’t check for data leakage here because it goes through each row instead of a chunk of data, which could slow down the process.
You can leave a message in the community discussion page for any feedbacks, or your evaluation got stuck at some point. The admin can interrupt the job.